
If you’re at all technically inclined – e.g. you’re a programmer, data scientist or snake milker – you probably figure that it wouldn’t be especially hard to make something like FindMyArea.
And to be honest, you’d be right. The concepts behind FindMyArea are quite simple and your initial guesses probably aren’t that far off the mark.
So what’s the point of this article? Well, I’ve already written five sentences, and the sunk cost fallacy is part of my personal ethos.
Anyway, the devil is always in the details – you might want to know exactly what’s going on behind the scenes when FindMyArea recommends areas.
And that’s what this article is about.
What is FindMyArea?
FindMyArea helps you find the perfect area to live in.
It only handles London for now, but soon it’ll be the whole of the UK and then the entire multiverse.
You pop in the stuff you care about (budget, commute destinations, local amenities etc) and then the tool will give you a list of areas (e.g. Hackney or Richmond) that satisfy your requirements.
They say a picture is worth a thousand words, so here’s a 4K explanation.

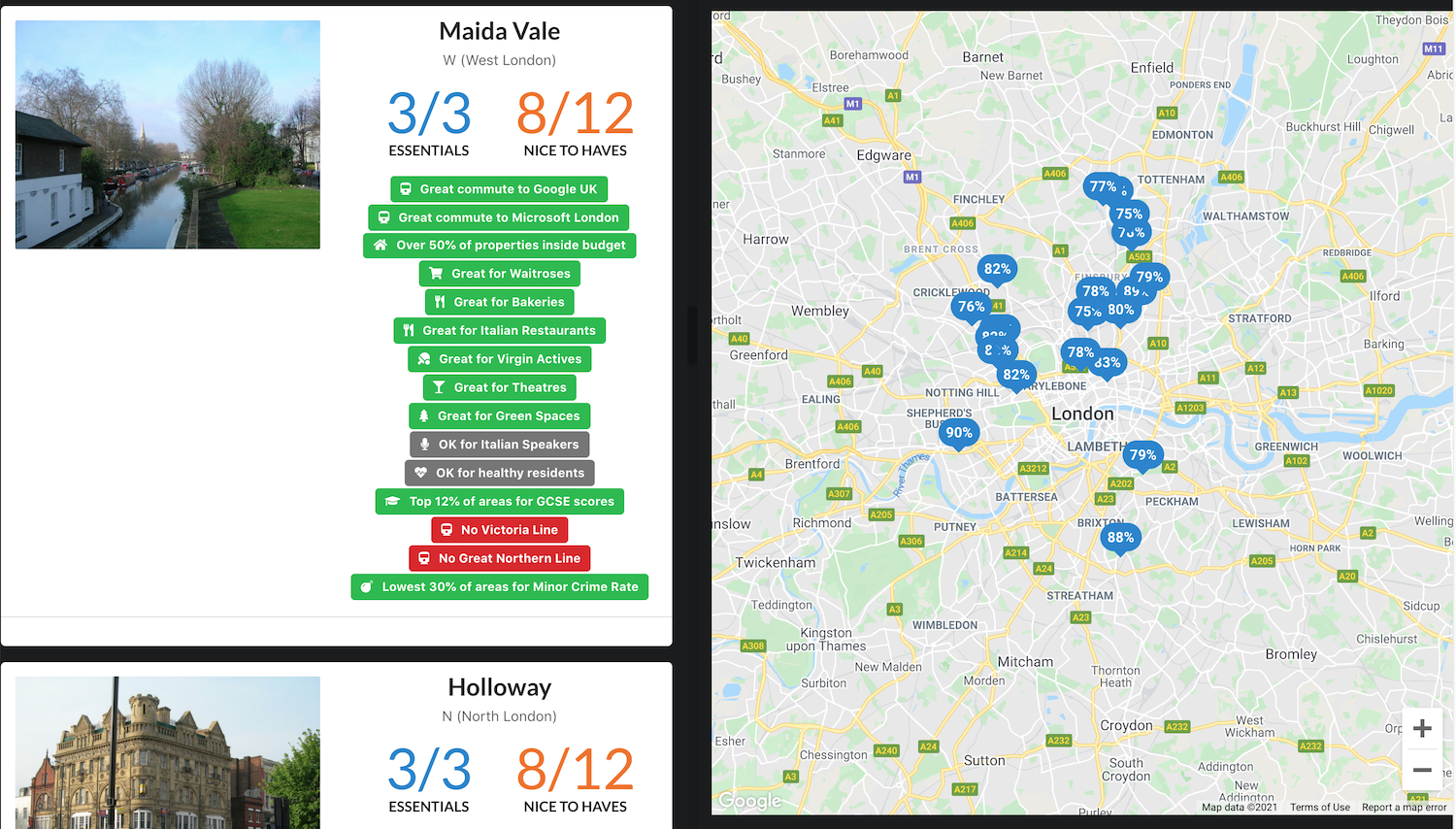
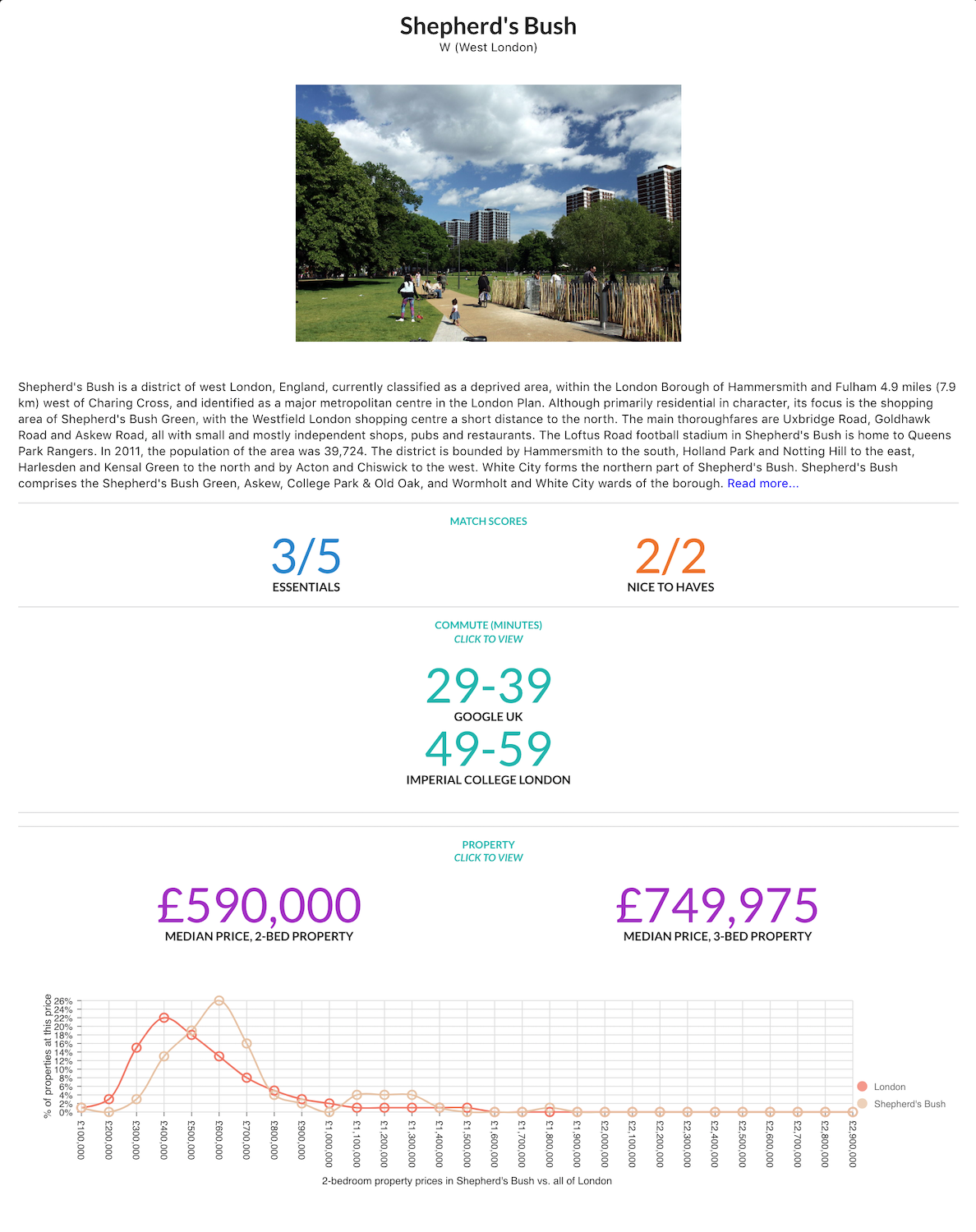
There are some other nice little features – if I do say so myself.
For example, you can save your search to a shareable link. It’s also kinda fun to play around with the criteria using the Edit Filters button to see how that affects the results.
bUt hOw dOeS iT wOrK?
At its core, FindMyArea is just a scoring engine that scores and ranks a bunch of neighbourhoods (“areas”) in London based on the criteria you’ve selected.
These kinds of scoring engines are conceptually simple but can be used for all sorts of things where you need to arrive at a decision based on multiple (possibly competing) criteria.
Such as if you want to find a holiday destination based on your budget and what you’d like to see/do. Or if you want to rank interview candidates according to their technical skills and the quality of their handshakes.
The FindMyArea scoring engine needs to:
- Score every area
- Against each of your chosen criteria
- And combine each individual criterion score into an aggregate score (one per area) that makes intuitive sense
Preferably in a way that allows each area to be scored against any criterion in a consistent and comparable way.
Let’s talk a bit about that “consistency” thing.
Criteria come in all shapes and sizes: you might want to live in a safe neighbourhood, but you also want to stay within your property budget, because living beyond your means also makes you feel unsafe. And ideally there’d be a Waitrose nearby – because you’re too posh for Aldi – and you want a quick commute to the City.
But in order to compute a single score for an area, we can’t do something like “take the number of Waitroses in the area and subtract the time it takes to commute to the City”. The units and scales aren’t comparable.
How well an area satisfies each criterion needs to be quantified, then, with a set of consistent and comparable “units” that works regardless of what the specific criterion is.
FindMyArea does this by marking each area as “great”, “good”, “borderline” or “bad” with respect to each criterion.
Exactly what makes an area “great” or “bad” for a criterion depends on what that criterion actually measures. If it’s a Waitrose criterion, any more than zero Waitroses in the area is enough to make the area good for Waitroses.
But if you like Indian restaurants, then you’ll probably want more than one in the area, so the criterion is a little tougher in this case.
If it’s a safety criterion, being in the top 10% of the safest neighbourhoods in London will qualify an area as “great for safety”. And so on and so forth for each criterion.
Criteria can be marked by the user as “essential”, “nice to have” or “don’t care”.
Why isn’t this more granular, say letting the user prioritise each criterion with scores from 1 to 10?
It’s a bit subjective, but I think it’s annoying to try to quantify how important each criterion is to you at that level of detail.
I find that the breakdown into “essential”, “nice to have” and “don’t care” matches the level of granularity at which I normally think about these things, and I’ve basically just assumed everyone else is like me.
Anyway, I’d like to talk about how these criterion states are used. If a criterion is marked as “don’t care”, the scoring engine ignores it. Shocking, I know.
Essential criteria really are considered as “essential”! It’s a hard filter: areas that aren’t at least a “good” for these criteria will be nuked from the list of results. (If there’s even a small chance that you might be flexible on a criterion, put it in as a nice-to-have!)
This is the main reason FindMyArea might return zero results.
If you put in too many essential criteria, the engine will try to find areas that satisfy all these criteria and then tell you that you’re insane for thinking you can find a 3-bed flat within 15 minutes of Piccadilly Circus for under £500 per calendar month.
So FindMyArea is a bit of a literalist. But while being technically correct is the best kind of correct, if the engine can’t find (m)any areas that satisfy your exacting requirements, it’ll give you the option to also see areas that don’t quite match your essential criteria.
It’ll still prioritise your essential criteria, though, as areas receive higher scores for matching essential criteria than nice-to-haves. More on this below.
Enjoying this article?
Then join the FindMyArea beta program. You will:
- Get the latest features before anyone else
- Help shape the direction of FindMyArea
Scores galore
Ah yes, the exciting part! Or at least it would be, if simple formulae were exciting to you.
Let’s recap. The user gives us a set of essential and nice-to-have criteria. We have a way to assign each area a grade of “great”, “good”, “borderline” or “bad” with respect to each criterion.
Now what we need to do is turn this into a single score for each area that takes all the criteria into account.
To do this, we start by computing two scores for each area:
- An
essential_score, which is a score in[0, 1]that tells us how well the area satisfied all the essential criteria - A
nice_to_have_score, which is a score in[0, 1]that tells us how well the area satisfied all the nice-to-have criteria
Each of these scores is calculated in exactly the same way, so let’s just talk about the essential_score.
First, for each area and each individual essential criterion we compute an “area’s essential criterion score” (I usually try to avoid inventing abbreviations and acronyms, but I’m just going to write AECS from now on).
The AECS is just a non-negative integer, like the number 3 or the number 4,294,967,296.
Areas that are “great” for a criterion receive a high AECS, those that are “good” receive a slightly lower AECS and… well, you get the picture.
To obtain the essential_score for each area, FindMyArea simply adds these AECSs together and normalises them to between 0 and 1.
And each area’s nice_to_have_score is computed in the same way.
Note that the final single score for each area needs to prioritise essential criteria over those that are merely nice to have. So we calculate an area’s final overall score as the weighted average of the essential_score and nice_to_have_score, with the essential_score receiving a higher weight than the nice_to_have_score.
Actually, I lied a little when I said we wanted to have a single score for each area. FindMyArea only uses these scores in the map view (that’s what those percentages are).
The actual ranking of areas in the list view is simply an ordering by (essential_score, nice_to_have_score). This is because we always want essential criteria to be prioritised over nice-to-have criteria, even in the scenario where we have a huge number of nice-to-have criteria.
Finally, we also return simple counts of the essential and nice-to-have criteria that are satisfied by each area. This is easy for the user to understand, but unlike the scores it doesn’t have any notion of how well each criterion is satisfied.
And that’s it! Hey, I told you this wasn’t complicated :-P
Aggressively aggregated statistics
Needless to say, FindMyArea needs access to data so it can do its thing. The data sources I use are listed here.
After pulling in all the raw data it needs, FindMyArea does a bunch of number crunching to precompute various statistics for each area.
Examples: the distribution of 1-bedroom flat prices is stored for each area. And the number of good bakeries in each area is also stored, because highly processed white bread is no longer good enough for the discerning glutton.
What’s an “area”?
This is one of those simple-sounding questions that has an annoyingly complex answer. Any definition of “area” we come up with would have to satisfy the following conditions:
- It can’t be too small
- It can’t be too big
- It needs to have a name that makes sense to the user (e.g. you might say “I live in Crouch End”, but you wouldn’t say “I live in the MSOA called Ealing 032”)
- It needs to have precise geographical boundaries
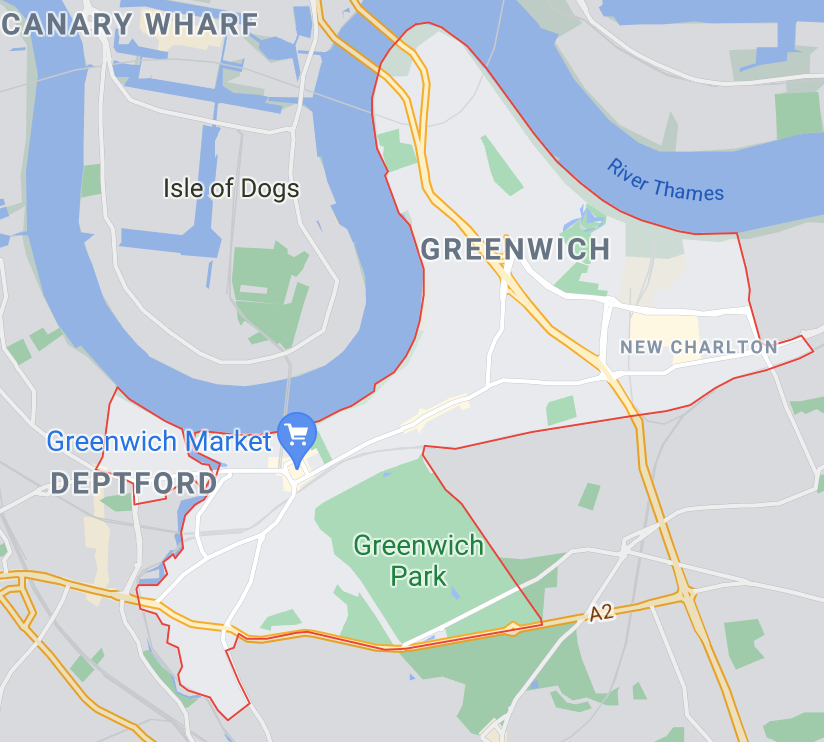
Ideally there also shouldn’t be a massive overlap between areas, but I decided not to be too pedantic about that.
When I started trying to build a good list of areas for London, I realised that there simply wasn’t any existing list that satisfied all these conditions, so I just built my own using Wikipedia as a starting point.
Here’s a little problem for the reader: how do you decide if, say, an Italian restaurant is “in” an area?
Answering this question literally shows that the question itself is not very good. If the restaurant lies just outside the boundaries of a fairly small area, it would still be considered easily reachable from the area – and ultimately “easily reachable” is all the user cares about.
So let’s revise the question: how do you decide if an Italian restaurant is easily reachable from an area?
OK, I’ll admit it… I’m not sure if there really is a great answer to this question. Some areas are big enough that a restaurant that’s easily reachable from one part of the area might not be easily reachable from another.
You could perhaps address this by accepting any restaurant that is easily reachable by, say, 75% of the area’s population. Or perhaps divide bigger areas into smaller chunks, so we have made-up neighbourhoods like “North Marylebone” or “South Highgate”.
But for now, I’ve just gone with a simple hack. (FindMyArea is supposed to be an MVP after all.) I don’t even worry about specifying area geometries properly: I just define each area to be a circle, and then if a restaurant is within that circle I say it “belongs” to the area.
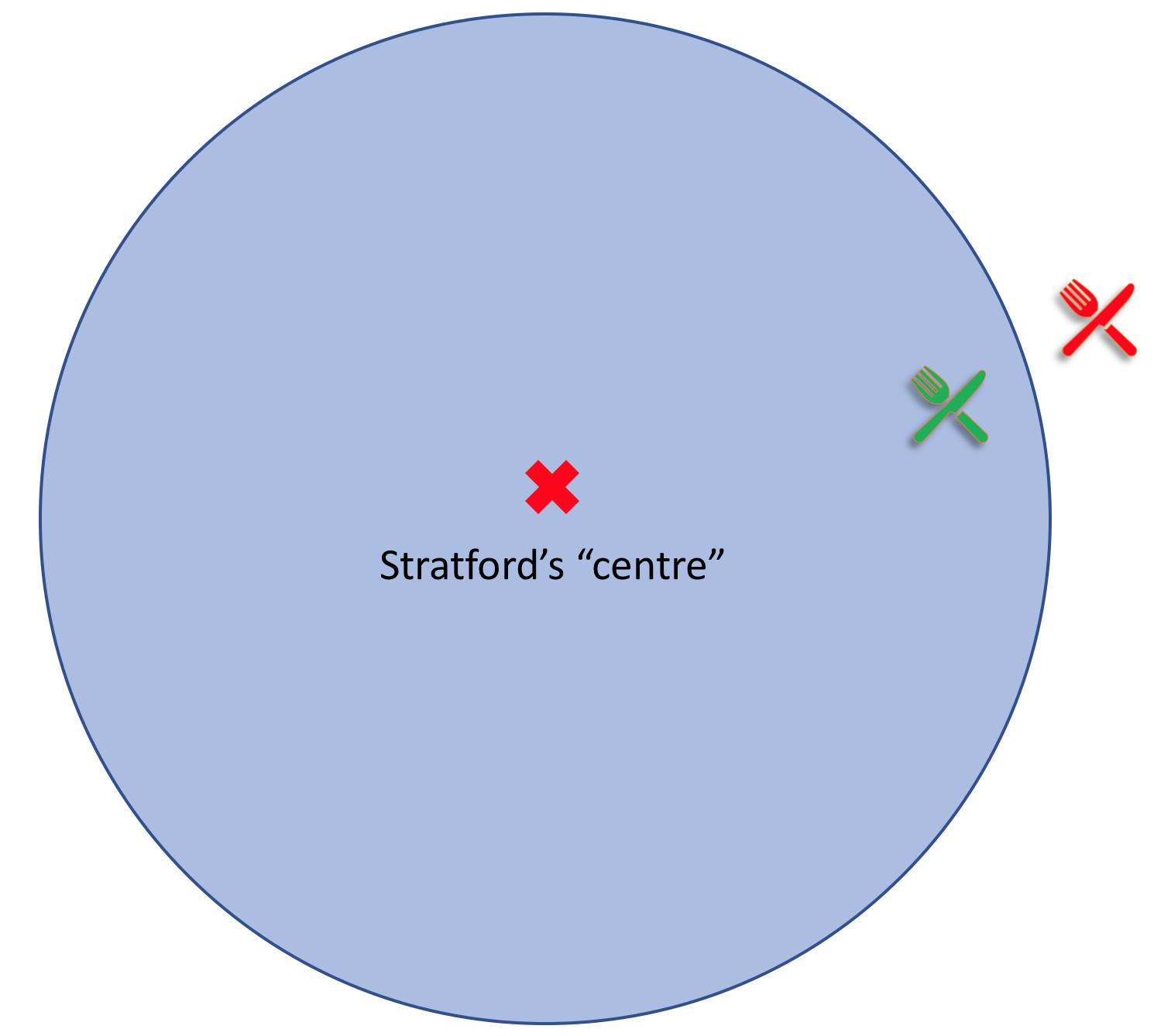
Empirically this actually works way better than you’d expect, though it does occasionally lead to odd results! I’ll fix it once enough people say it’s making their results bad ;-)
Enjoying this article?
Then join the FindMyArea beta program. You will:
- Get the latest features before anyone else
- Help shape the direction of FindMyArea
Hey, aren’t you a data scientist? Where’s the clever machine learning?
Not every problem benefits from machine learning, and I think this is one such example – at least in the current incarnation.
Basically, the reason there’s no ML is the same reason that Rightmove and Zoopla just ask you to put in your requirements and then give you a bunch of matching properties. It’d be pretty annoying if they instead tried to “learn” your preferences even when you already have a clear idea of what you want.
Fundamentally, if the user has a set of explicit preferences, then I’d rather respect those requirements than spend a lot of time trying to come up with a clever way to learn said preferences from the user’s actions.
Would a Tinder-esque interface, with each area displayed on its own card with its full set of characteristics, work well?
You could imagine that you swipe right if you like an area and left to dismiss it. And then there could be some active learning in the background, figuring out what floats your boat and giving you more of what you like as you keep swiping.
But for the moment, this seems a bit like trying to use a hammer to crack an egg. There are only a few hundred areas in London, so an interface like that would probably be overkill. It might be something interesting to explore if FindMyArea needed to sort through 10-100x more areas (e.g. because you want to find smaller areas or you’re looking across an entire country).
Anyway, for quickly finding areas that match your requirements, I think the current approach is likely to be superior to any ML-based approach. But perhaps this is something I’ll look into more if I start incorporating more “browsing/exploring” features into the website, as opposed to the existing focus on search.
I hate overengineering, though, so I’d need to be convinced that this is solving a real problem :-P
Stuff I’d like to improve
Ooh, where to begin! Eventually I’d like to turn FindMyArea into a tool where you can find the right area for anything.
Not just finding areas to live in, but also areas that are ripe for investment or relocating to if you’re a digital nomad (or for the perfect holiday, if that’s more your thing).
Currently the only way you can do this is using GIS software, and ain’t nobody got time to learn that stuff.
But that’s still a distant goal at this point. Broadly what I’m thinking right now is:
- Enabling much more granular areas, so you know exactly which parts of Walthamstow are a good fit. Ideally the user should be able to choose any level of granularity – from a small postcode sector to an entire region.
- Improving the way in which you specify your criteria: the current approach seems a bit clunky. Building a natural language interface is tempting from a wow factor point of view, but it’d arguably be a solution in search of a problem ;-)
- Adding more criteria based on data like:
- Broadband/mobile coverage
- Planning permissions granted
- Trends, e.g. if rents have suddenly dropped or there are lots of new chicken shops in an area
- Figuring out how to get more data for subjective things like “vibe” and “character”
- Expanding from London to the rest of the country and then the WHOLE WORLD (data permitting ;-))
- Boring stuff like improving the way in which areas are defined and how some of the criteria are defined (e.g. the way the green space data is incorporated is a bit iffy, and there’s loads more I could do on school catchment areas)
This is bound to change a lot over time though, most of all based on the feedback and feature requests I receive. Ultimately this is driven by what the user wants, not my “grand vision”.
If you want to have your say, I’d love to hear what you think: you might like to join the beta program or just drop me a message the old-fashioned way.